在 YOLOv12 中移植 DMMA 的过程与训练记录
YOLOv5 方案要点
WindowAttention+minusSigmoid构成 DMMA(models/newMSA3.py:24-110),对 q/k/v/m 做归一化、差分掩码计算再送入 softmax。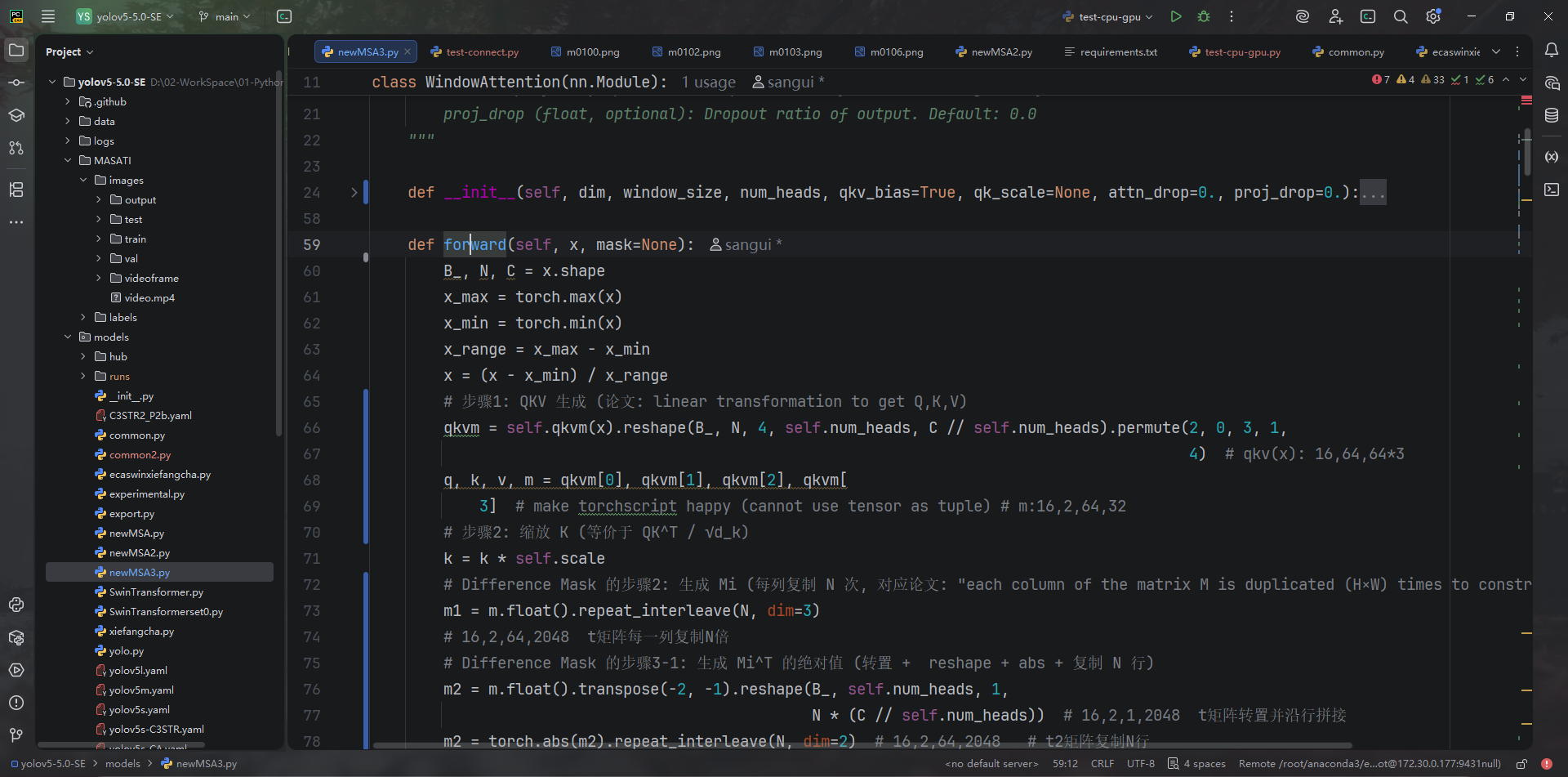
SwinTransformerLayer在窗口注意力输出后乘以 ECA 通道权重、并交替使用 SW-MSA(models/newMSA3.py:309-356)。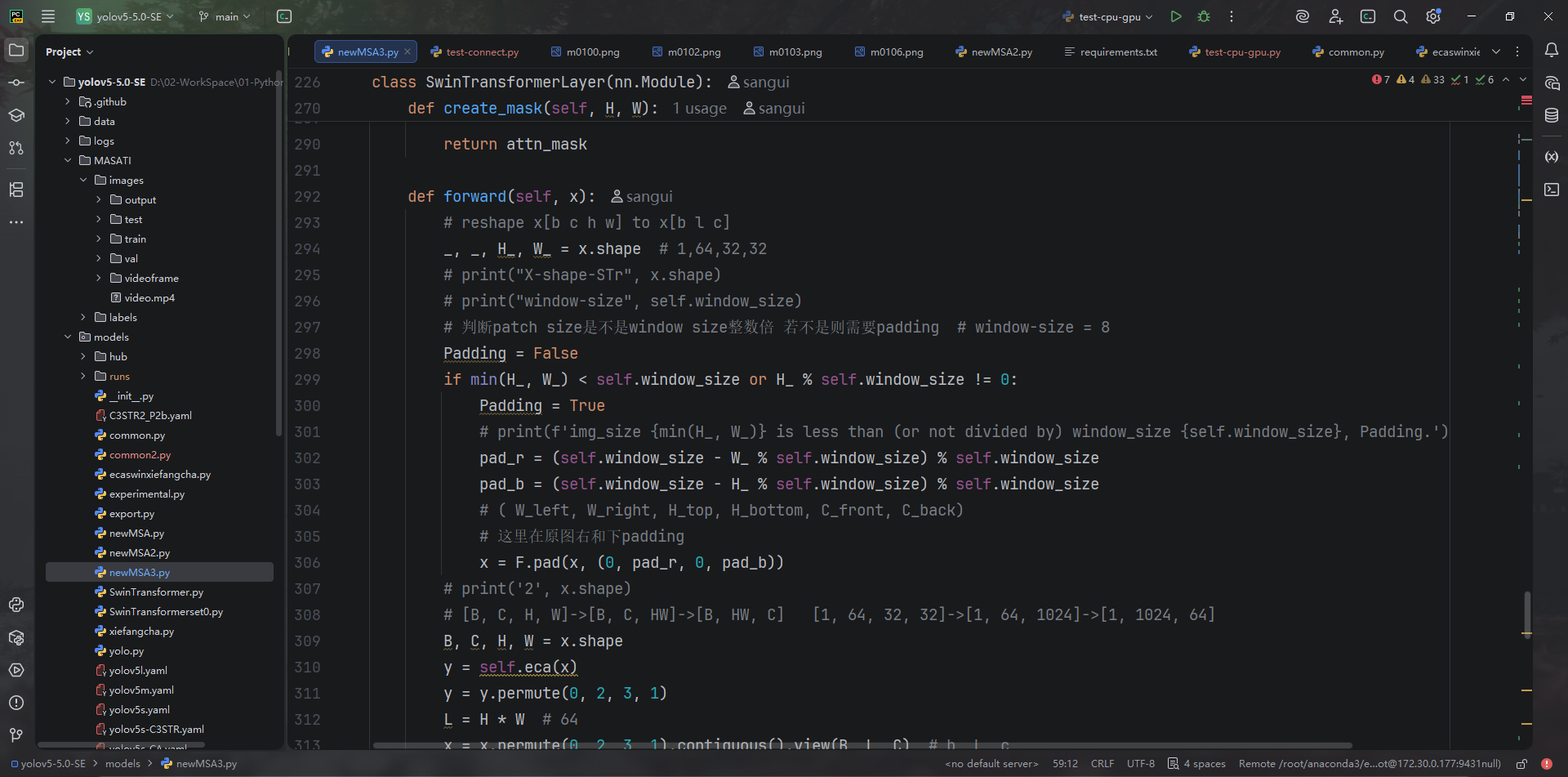
C3STR将上述 Swin 块内嵌到 C3 结构 (models/common2.py:367-379),并在椭圆 YAML 中用于检测头。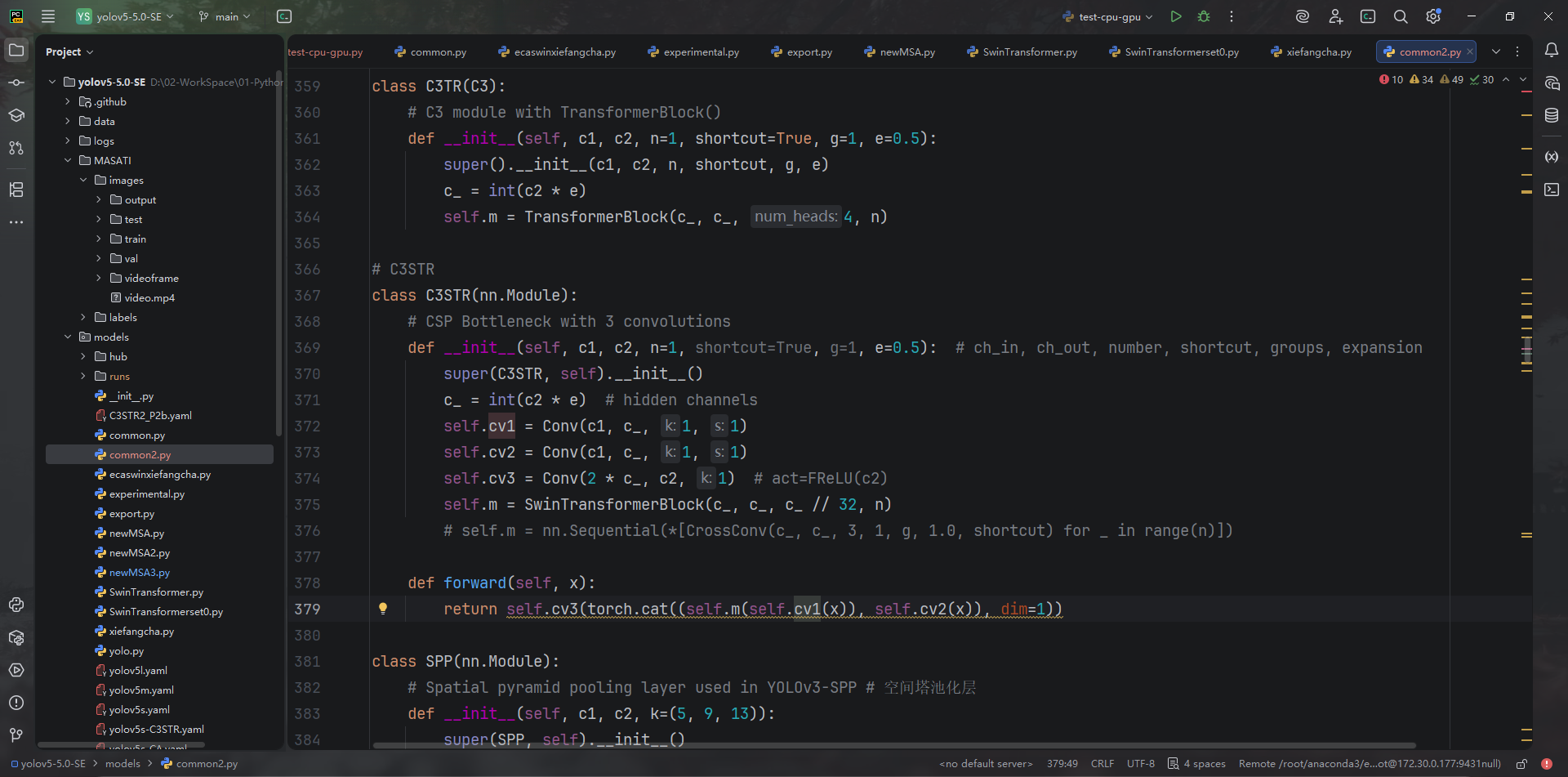
当前 YOLOv12 实现
ultralytics/nn/modules/transformer.py:431-696新增DMMALayer:重写 DMMA、ECA、DropPath、窗口划分等,移除 timm 依赖。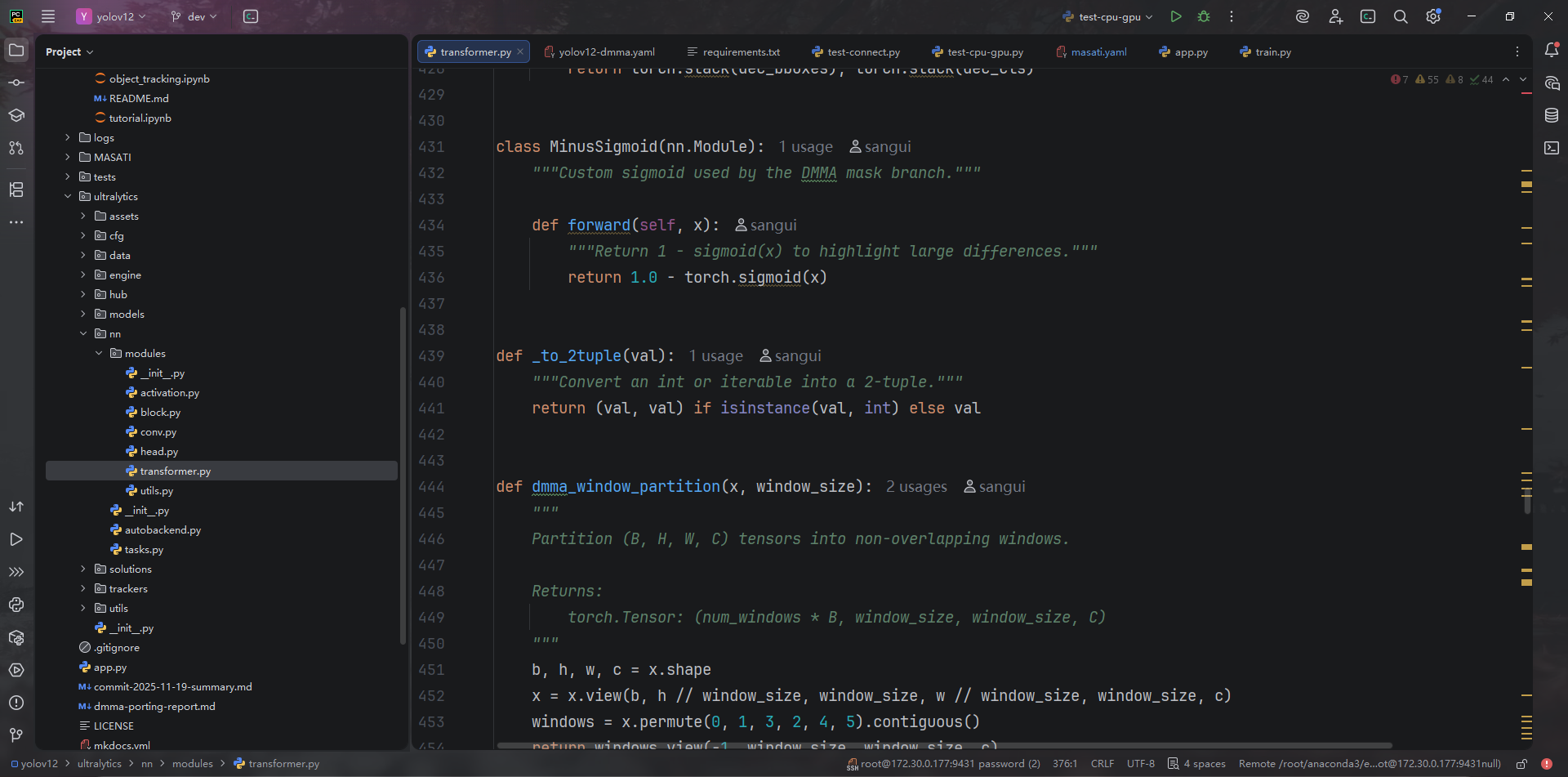
ultralytics/nn/modules/block.py:475-517定义C2fDMMA,以 YOLOv12 默认的 C2f 结构封装 DMMA block。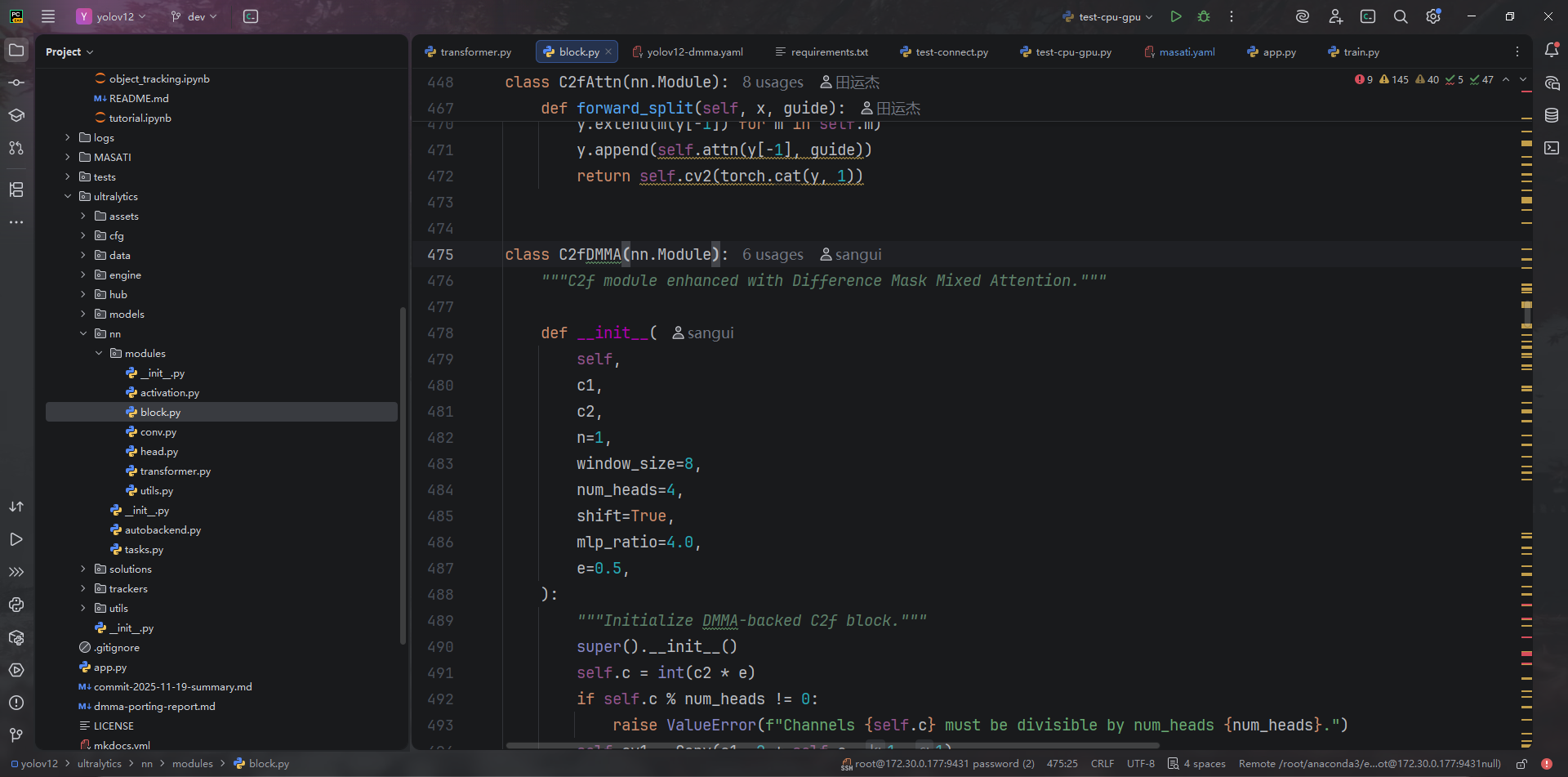
ultralytics/nn/modules/__init__.py:26、ultralytics/nn/tasks.py:32、ultralytics/nn/tasks.py:983、ultralytics/nn/tasks.py:1018将新模块注册到构建流程。ultralytics/cfg/models/v12/yolov12-dmma.yaml:15-45给出全新的 backbone/head,P4/P5 backbone 与 P3–P5 head 均替换为C2fDMMA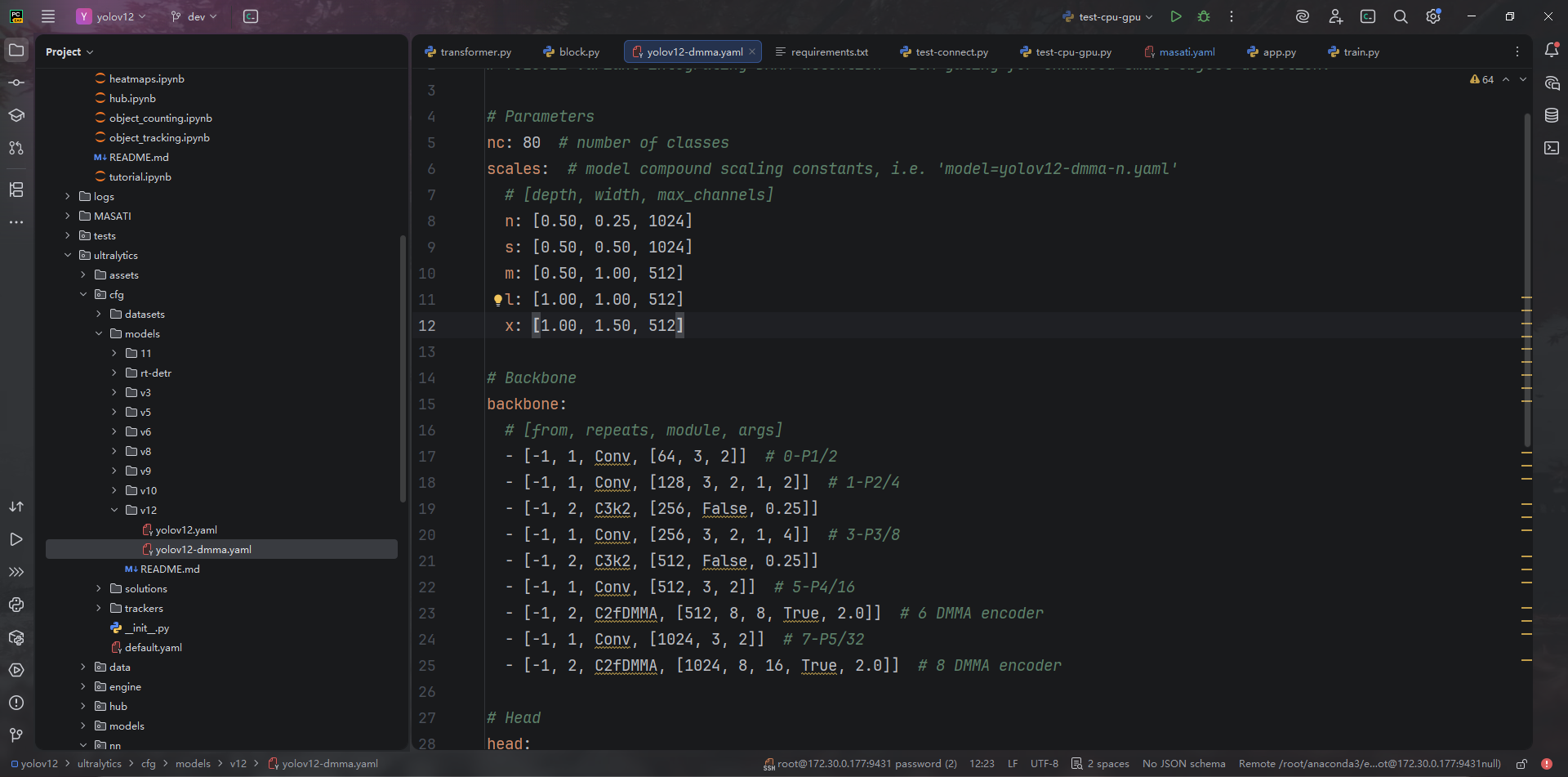
移植一致性与差异
| 项目 | YOLOv5 (来源) | YOLOv12 (现状) | 备注 |
|---|---|---|---|
| 注意力核心 | WindowAttention + 差分掩码 (newMSA3.py:24-110) | DifferenceMaskAttention (transformer.py:431-550) | 逻辑一致,但实现语言改为纯 PyTorch,无 timm 依赖 |
| 通道门控 | ECA 乘性增强 (newMSA3.py:309-347) | DMMAChannelAttention (transformer.py:572-585) | 功能相同 |
| 基本单元 | C3STR (common2.py:367-379) | C2fDMMA (block.py:475-517) | 结构换成 C2f,更贴合 YOLOv12 |
| Shift Window | SwinTransformerBlock 固定交替 shift (common2.py:289-298) | 通过 shift 参数控制 (block.py:497-503) | Backbone 传入 True,Head 目前配置为 False |
| Head num_heads | 自动 c_/32 (common2.py:375) | YAML 中固定 8 (yolov12-dmma.yaml:31-39) | P3/P4/P5 相同,未随通道数缩放 |
| MLP 扩展比 | 默认 4 (newMSA3.py:244-268) | Backbone 2.0、Head 1.5 (yolov12-dmma.yaml:23-39) | 更轻量但与旧设定不同 |
训练步骤
Step1 配置环境
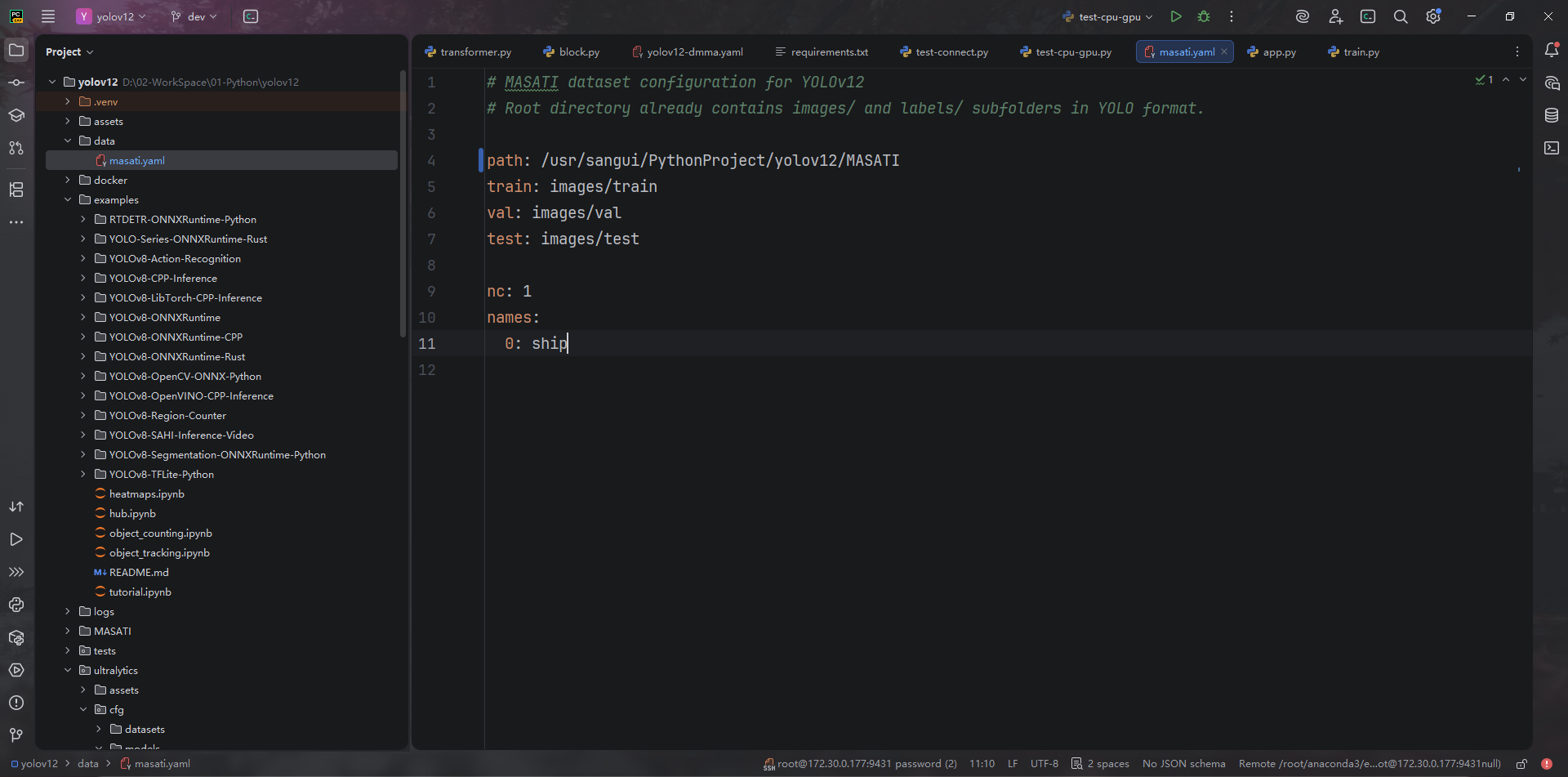
Step2 配置数据集信息
Step3 训练命令
CUDA_VISIBLE_DEVICES=2 yolo detect train \
model=ultralytics/cfg/models/v12/yolov12-dmma.yaml \
data=data/masati.yaml \
imgsz=640 \
batch=32 \
epochs=300 \
device=0 \
workers=8 \
project=runs/detect \
name=dmma_masati_gpu2_b24 \
lr0=0.01 \
scale=0.5 \
mosaic=1.0 \
mixup=0.1 \
copy_paste=0.2 \
amp=FalseStep4 训练
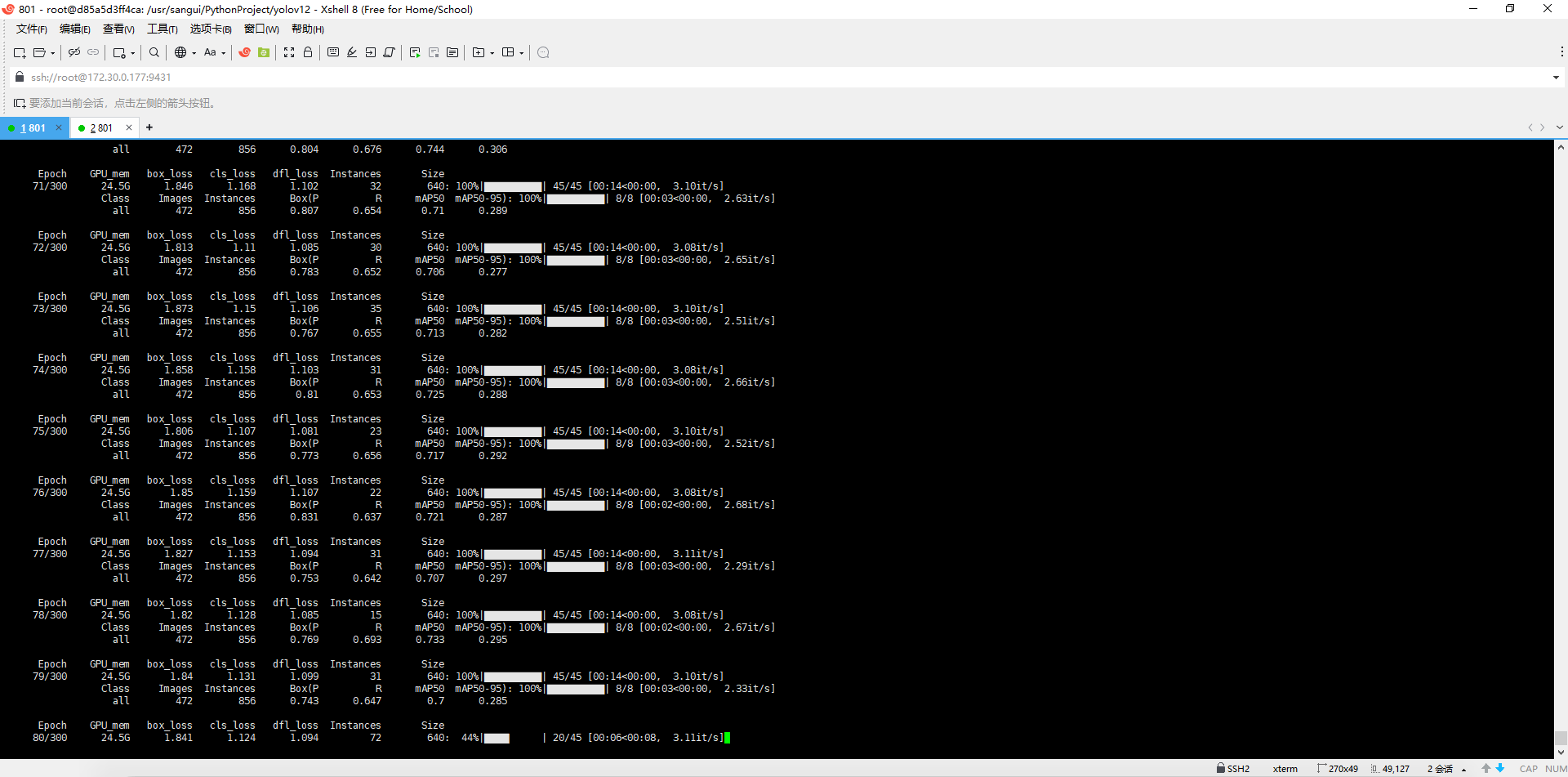
训练部分每个 epoch 大约 14 秒,验证大概 3–4 秒。
所以一整个 epoch(训练 + val):18 秒/epoch。
现在是 300 个 epoch,那总时间大约是:300 × 18 秒 ≈ 5400 秒 ≈ 1.5 小时
Step5 结果展示
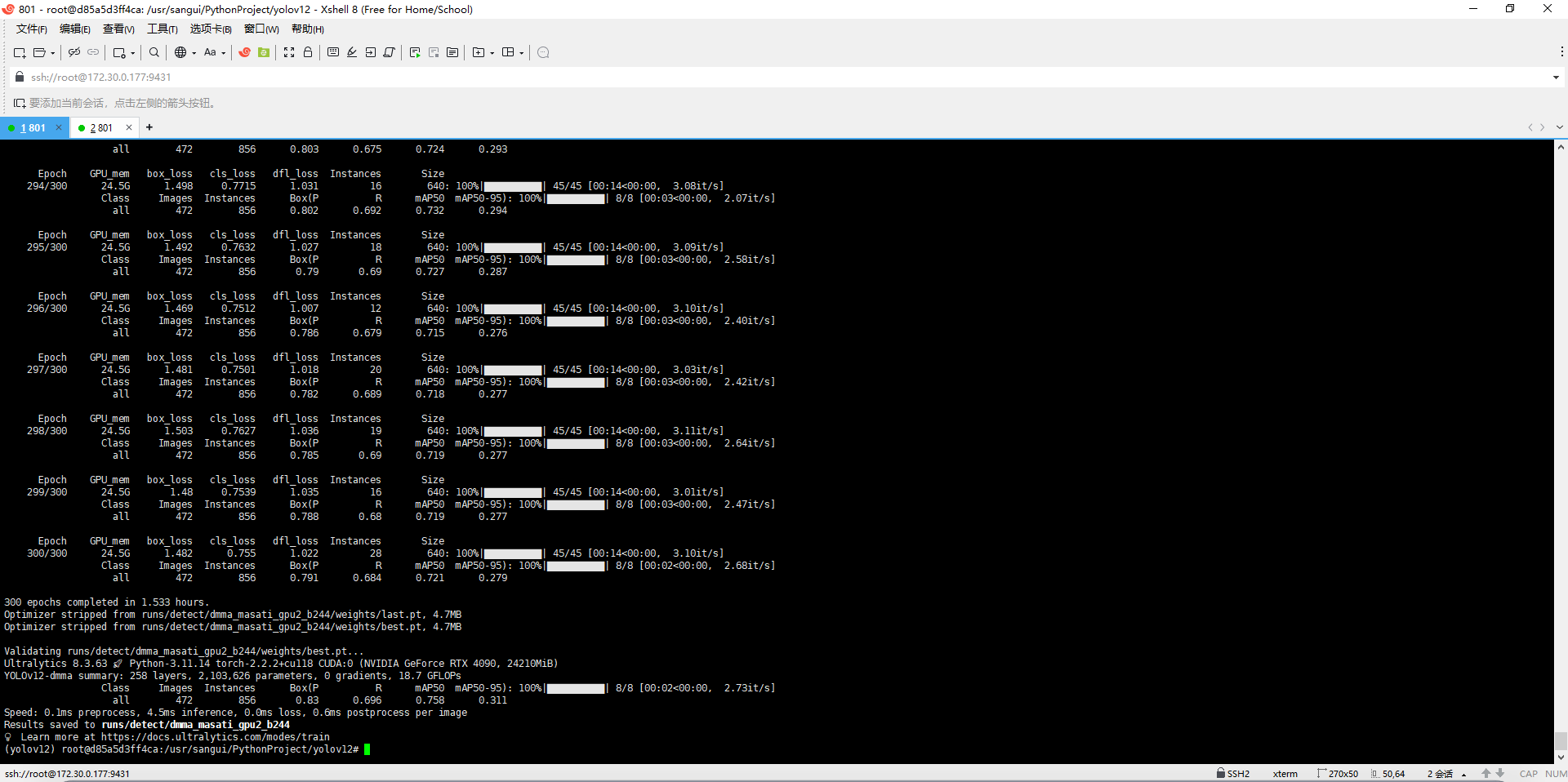
mAP50:0.758(75.8%)
Precision ≈ 0.90
Step6 下一步训练
# 用上一轮最好的权重继续训练
yolo detect train \
model=runs/detect/dmma_masati_gpu24/weights/best.pt \
data=data/masati.yaml \
imgsz=1024 \
batch=24 \
epochs=100 \
device=2 \
workers=8 \
project=runs/detect \
name=dmma_masati_gpu2_img1024 \
lr0=0.01 \
scale=0.5 \
mosaic=1.0 \
mixup=0.1 \
copy_paste=0.2 \
multi_scale=True \
close_mosaic=20 \
amp=True
- 微信
- 赶快加我聊天吧

- 赶快加我聊天吧

2025年12月13日 18:09:48 1楼
终于看懂一个哈哈,跑的数据集是啥coco?
2025年12月13日 19:09:42 1层
@ 帅 是滴,嘿嘿